Appium + mitmproxy 全自动化抓取APP 数据
背景
公司新接到一个某某公司的一个项目需求,其中有一个子项是抓取诸如今日头条、网易新闻、腾讯新闻等新闻类 APP 的新闻,远端根据一个关键词或者一个主账号名称查找获取关于该关键词的所有新闻或主账号下的所有文章,通过简单的抓包分析,发现只有少数 APP 网络请求参数未做签名处理,像这类的能直接分析 url 和 param,利用 python 全自动化获取数据,但是大部分比如网易新闻这类 APP 安全级别较高,参数做了加密或者签名校验,服务端也有同一签名的请求访问次数限制,所以在这样的情况下想要直接获取通过外部调用获取数据几乎变得不可能。
分析
在以上的背景之下,简单分析和调研之后,觉得有以下办法可以获取到那些请求加密的 APP 的数据,如下:
- 逆向分析该 APP,揪出加密方法及对应的逻辑,第三方使用同样的逻辑加密请求参数获取数据;
- 寻找该新闻 APP 在 WEB 端的接口,同样也能获取到数据;
- 对 APP 使用网络代理,使用手机获取新闻,使用中间人攻击(MITM)获取数据 并做对应处理。
这三个方案中,第一种,难度最大,因为了解所有明白,以我的逆向水平暂时达不到,虽然可行,但暂时不考虑;第二种,经验证,很多在 APP 端有的接口在 WEB 端没有,也放弃;第三种,面临几个问题,因为整个过程要全自动化,所以这个操作使用获取新闻的过程要自动,手机获取到新闻后数据抓取的过程要自动,这就意味着不能使用 Wireshark、Charles、Fiddler 等抓包工具人为干预,要解决这两个问题,即要解决这两个问题:
- 使用脚本自动化 UI 操作
- 代理软件能与脚本交互
Q:Appium 是什么?
A:Appium 是一个自动化测试开源工具,支持 iOS 平台和 Android 平台上的原生应用,web 应用和混合应用。
“移动原生应用”是指那些用 iOS 或者 Android SDK 写的应用。
“移动 web 应用”是指使用移动浏览器访问的应用(Appium 支持 iOS 上的 Safari 和 Android 上的 Chrome)。
“混合应用”是指原生代码封装网页视图——原生代码和 web 内容交互。比如,我们在微信里可以查看网页,可以通过网页应用买电影票等。
Appium 适配了与诸如 JAVA、Python、Javascript、Ruby 等众多语言的交互,我选择 Python,即:Appium + python
为解决第二个问题,找到了两个解决方案,第一个是 mitmproxy,Github主页,第二个是AnyProxy,Github主页,这两个都是开放式的HTTP/HTTPS代理服务,后者是阿里巴巴基于 Node.js 开发的一款开源代理服务,前者是一款免费开源的可交互的HTTP/HTTPS代理服务,可与 Python 交互,且功能更强大,我选择了后者,即:mitmproxy + python
编码
方案已经确定了,就开始看文档进行编码工作,过程与细节就不写了,直接上成果。
自动操作 UI 部分
#!/usr/bin/python3
from appium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from appium.webdriver.common.touch_action import TouchAction
import time
import sys
import getopt
import json
import os
import selenium
import argparse
platformName = 'iOS'
deviceName = 'iPhone 6s'
bundleId = 'com.netease.news'
udid = 'your_uuid'
automationName = 'XCUITest'
xcodeOrgId = 'your_ xcodeOrgId'
xcodeSigningId = 'your_certificate_name'
driverServer = 'http://127.0.0.1:4723/wd/hub'
class Input:
type = ''
keyWord = ''
class NeteaseNewsSpider():
def __init__(self):
self.desired_caps = {
'platformName': platformName,
'deviceName': deviceName,
'bundleId': bundleId,
'udid': udid,
'automationName': automationName,
'clearSystemFiles': True,
}
self.driver = webdriver.Remote(driverServer, self.desired_caps)
def tearDown(self):
self.driver.quit()
def performActionForKeyword(self, keyWord):
driver = self.driver
wait = WebDriverWait(driver, 300)
time.sleep(5)
try:
el1 = wait.until(EC.presence_of_element_located(
(By.XPATH, '//XCUIElementTypeApplication[@name=\"网易新闻\"]/XCUIElementTypeWindow[1]/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther[1]/XCUIElementTypeButton[1]')))
except selenium.common.exceptions.NoSuchElementException:
pass
el1.click()
time.sleep(0.5)
TouchAction(self.driver).tap(x=206, y=44).perform()
print('输入目标关键词:%s' % keyWord)
el3 = wait.until(EC.presence_of_element_located(
(By.XPATH, '//XCUIElementTypeApplication[@name=\"网易新闻\"]/XCUIElementTypeWindow[1]/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther/XCUIElementTypeOther[1]/XCUIElementTypeOther/XCUIElementTypeTextField')))
el3.send_keys(keyWord)
print('点击搜索按钮')
el3.send_keys('\n')
def findForKeyWord(self, keyWord):
self.performActionForKeyword(keyWord)
time.sleep(0.5)
print('动作结束')
os.system('say 动作结束')
def findForUser(self, keyWord):
driver = self.driver
self.performActionForKeyword(keyWord)
time.sleep(0.5)
# 点击用户
print('点击用户')
el1 = driver.find_element_by_xpath(
"//XCUIElementTypeOther[@name=\"i\"]/XCUIElementTypeOther[1]/XCUIElementTypeOther[4]")
el1.click()
time.sleep(0.5)
# 点击用户第一个
if self.isExistElement(By.XPATH, '//XCUIElementTypeOther[@name=\"i\"]/XCUIElementTypeOther[2]/XCUIElementTypeOther[1]/XCUIElementTypeOther[1]/XCUIElementTypeImage'):
print('点击用户列表第一个')
el2 = driver.find_element_by_xpath(
"//XCUIElementTypeOther[@name=\"i\"]/XCUIElementTypeOther[2]/XCUIElementTypeOther[1]/XCUIElementTypeOther[1]/XCUIElementTypeImage")
el2.click()
else:
print('没有相关用户')
os.system('say 无相关用户')
time.sleep(0.5)
print('动作结束')
os.system('say 动作结束')
def scrollUp(self):
self.driver.execute_script("mobile: scroll", {"direction": "down"})
def isExistElement(self, identifyBy, c):
'''
判断元素是否存在
用法:
isExistElement(By.XPATH,"//a")
'''
time.sleep(0.5)
flag = None
try:
if identifyBy == "id":
#self.driver.implicitly_wait(60)
self.driver.find_element_by_id(c)
elif identifyBy == "xpath":
self.driver.find_element_by_xpath(c)
elif identifyBy == "class":
self.driver.find_element_by_class_name(c)
elif identifyBy == "link text":
self.driver.find_element_by_link_text(c)
elif identifyBy == "partial link text":
self.driver.find_element_by_partial_link_text(c)
elif identifyBy == "name":
self.driver.find_element_by_name(c)
elif identifyBy == "tag name":
self.driver.find_element_by_tag_name(c)
elif identifyBy == "css selector":
self.driver.find_element_by_css_selector(c)
flag = True
except selenium.common.exceptions.NoSuchElementException:
flag = False
finally:
return flag
def spiderForKeyWord(keyWord):
print('查找关键词:%s' % keyWord)
spider = NeteaseNewsSpider()
spider.findForKeyWord(keyWord)
def spiderForUser(keyWord):
print('查找用户:%s' % keyWord)
spider = NeteaseNewsSpider()
spider.findForUser(keyWord)
def main():
type = Input.type
keyWord = Input.keyWord
if type == 'keyword':
spiderForKeyWord(keyWord)
elif type == 'user':
spiderForUser(keyWord)
if __name__ == "__main__":
description = u"自动化 UI 操作,查找网易新闻"
parser = argparse.ArgumentParser(description=description)
parser.add_argument('-k', dest='keyWord', type=str,
help='必填:关键词名字', required=True)
parser.add_argument('-t', dest='type', type=str, choices=["keyword", "user"],
help='必填:查找类型', required=True)
args = parser.parse_args()
Input.type = args.type
Input.keyWord = args.keyWord
main()
代理部分分析和保存数据
addons.py
#!/usr/bin/python3
import joker
addons = [
joker.Joker()
]
common.py
#!/usr/bin/python3
import os
WORKING_DIR = "/Users/VanJay/Documents/Work/Tungee/新闻APP搜索接口破解情况/ant.git/netease_news_suite/"
DataBasePath = WORKING_DIR + 'data'
DataBaseKeywordPath = WORKING_DIR + 'data/' + 'Keyword'
DataBaseUserPath = WORKING_DIR + 'data/' + 'User'
AppiumPath = WORKING_DIR + 'appium'
MitmproxyPath = WORKING_DIR + 'mitmproxy'
SearchConfigPath = WORKING_DIR + 'currentSearchConfig.json'
NeteaseAccountJSON = '/neteaseAccount.json'
NeteaseAccountArticleJSON = '/neteaseAccountArticle.json'
def getParamValue(url, key):
defaultValue = None
list = [i.split("=")[-1] for i in url.split("?", 1)
[-1].split("&") if i.startswith(key + "=")]
if len(list) > 0:
value = list[0]
if value != '':
return value
else:
return defaultValue
else:
return defaultValue
def solveDirDependency():
if not os.path.exists(DataBasePath):
os.system('mkdir ' + DataBasePath)
def solveDestSearchOpDep(word):
path = DataBasePath + '/' + word
if not os.path.exists(path):
os.system('mkdir ' + path)
return path
Joker.py
#!/usr/bin/python3
import json
import mitmproxy.http
from mitmproxy import ctx, http
import os
import shutil
from common import getParamValue, solveDirDependency, solveDestSearchOpDep
from common import SearchConfigPath, NeteaseAccountJSON, NeteaseAccountArticleJSON
class Joker:
def __init__(self):
self.netease_news_host = 'c.m.163.com'
self.search_url = 'https://c.m.163.com/search/comp2/'
self.re_search_url = self.search_url + 'MA%3D%3D/'
self.relatedArticleURL = 'https://c.m.163.com/nc/recommend/relate/article/'
self.hotDiscussURL = 'https://c.m.163.com/reader/api/recommend/viewpoints?docid='
self.articlePrefix = 'https://c.m.163.com/news/a/'
self.videoArticlePrefix = 'https://c.m.163.com/news/v/'
self.commentURLPreFix = 'https://comment.api.163.com/api/v1/products/a2869674571f77b5a0867c3d71db5856/threads/'
self.commentURLSuffFix = '/app/comments/hotModuleList?ibc=newsappios'
self.netesaeAccountProfileURL = 'https://c.m.163.com/uc/api/visitor/v3/simple/profile'
self.neteaseAccountArticleURL = 'https://c.m.163.com/nc/subscribe/list/'
self.newsTypeConfig = {
'zonghe': {'folderName': 'ZongHe'},
'shipin': {'folderName': 'Video'},
'tuji': {'folderName': 'Picture'},
'yonghu': {'folderName': 'User'}
}
# self.currentNewsType = 'zonghe'
# self.keyword = '关键词'
# self.searchType = 'keyword'
def request(self, flow: mitmproxy.http.HTTPFlow):
request = flow.request
url = request.scheme + '://' + request.host + request.path
# 网易新闻的搜索关键词接口
if url.startswith(self.search_url):
ctx.log.info("关键词搜索地址: %s " % request.pretty_url)
def response(self, flow: mitmproxy.http.HTTPFlow):
# 忽略非目标相关地址
if not flow.request.host in [self.netease_news_host, 'comment.api.163.com']:
return
request = flow.request
path = request.path
url = request.scheme + '://' + request.host + path
# 搜索(包含全新搜索和分页搜索加载)
self.dealingWithSearchResult(flow, path, url)
# 相关文章
self.dealingRelatedArticles(flow, path, url)
# 正在热议
self.dealingArticleHotDiscuss(flow, path, url)
# 文章热评
self.dealingComments(flow, path, url)
# 订阅号
self.dealingNeteaseAccount(flow, path, url)
# 订阅号文章
self.dealingNeteaseAccountArticle(flow, path, url)
def dealingWithSearchResult(self, flow: mitmproxy.http.HTTPFlow, path, url):
if url.startswith(self.search_url):
paramValue = getParamValue(url, 'tabname')
self.currentNewsType = 'zonghe' if paramValue == None else paramValue
# 搜索结果去掉为你推荐和网页结果
content = flow.response.get_content()
contentJson = json.loads(content)
contentJson['boxes'] = []
# 只要不是搜索用户就去掉网易号
if not self.currentNewsType == 'yonghu':
contentJson['topic'] = {}
flow.response.set_content((json.dumps(contentJson)).encode())
doc = {}
docResultList = []
topic = {}
topicResultList = []
if 'doc' in contentJson:
doc = contentJson['doc']
if 'result' in doc:
docResultList = doc['result']
if 'topic' in contentJson:
topic = contentJson['topic']
if 'result' in topic:
topicResultList = topic['result']
# 读取当前关键词
if not os.path.exists(SearchConfigPath):
os.system('say 搜索配置不存在,请确认')
exit()
# 检查依赖
solveDirDependency()
with open(SearchConfigPath, 'r') as file:
fileJson = json.load(file)
self.keyword = fileJson['keyword']
self.searchType = fileJson['type']
# 创建目标文件夹
self.currentSavePath = solveDestSearchOpDep(self.keyword)
print('currentSavePath:' + self.currentSavePath)
# 点击了重新搜索,而不是分页的继续搜索
if url.startswith(self.re_search_url):
print('点击了重新搜索')
if self.currentNewsType != 'yonghu':
with open(self.getCurrentSearchTypePath() + '/doc.json', 'w') as file:
file.write(json.dumps(doc, sort_keys=True,
indent=4, ensure_ascii=False))
with open(self.getCurrentSearchTypePath() + '/result.json', 'w') as file:
for item in docResultList:
item['postURL'] = self.articlePrefix + item['postid'] + \
'.html?spss=newsapp&from=singlemessage'
file.write(json.dumps(
docResultList, sort_keys=True, indent=4, ensure_ascii=False))
else: # 用户
with open(self.getCurrentSearchTypePath() + '/topic.json', 'w') as file:
file.write(json.dumps(topic, sort_keys=True,
indent=4, ensure_ascii=False))
with open(self.getCurrentSearchTypePath() + '/result.json', 'w') as file:
for item in topicResultList:
if 'ename' in item:
item['profileURL'] = self.netesaeAccountProfileURL + item['ename'] + \
'.html?spss=newsapp&from=singlemessage'
file.write(json.dumps(
topicResultList, sort_keys=True, indent=4, ensure_ascii=False))
# 网易新闻的搜索关键词接口(分页继续加载)
else:
print('分页继续搜索')
if self.currentNewsType != 'yonghu':
# 读取已保存数据
with open(self.getCurrentSearchTypePath() + '/result.json', 'r') as file:
oldResult = json.load(file)
# 拼接新数据
newResultList = oldResult + docResultList
with open(self.getCurrentSearchTypePath() + '/result.json', 'w') as file:
for item in newResultList:
item['postURL'] = self.articlePrefix + item['postid'] + \
'.html?spss=newsapp&from=singlemessage'
file.write(json.dumps(
newResultList, sort_keys=True, indent=4, ensure_ascii=False))
else: # 用户
# 读取已保存数据
with open(self.getCurrentSearchTypePath() + '/result.json', 'r') as file:
oldResult = json.load(file)
# 拼接新数据
newResultList = oldResult + topicResultList
with open(self.getCurrentSearchTypePath() + '/result.json', 'w') as file:
for item in newResultList:
if 'ename' in item:
item['profileURL'] = self.netesaeAccountProfileURL + item['ename'] + \
'.html?spss=newsapp&from=singlemessage'
file.write(json.dumps(
newResultList, sort_keys=True, indent=4, ensure_ascii=False))
def dealingRelatedArticles(self, flow: mitmproxy.http.HTTPFlow, path, url):
if url.startswith(self.relatedArticleURL):
skipID = find_between(url, self.relatedArticleURL, '.html')
if not os.path.exists(self.getCurrentSearchTypePath() + '/releatedoc'):
os.system(
'mkdir ' + self.getCurrentSearchTypePath() + '/releatedoc')
content = flow.response.get_content()
contentJson = json.loads(content)
releatedocList = contentJson['releatedoc']
releatedocSkipName = self.getCurrentSearchTypePath() + '/releatedoc/' + \
skipID + '.json'
with open(releatedocSkipName, 'w') as file:
for item in releatedocList:
if item['type'] == 'doc':
item['postURL'] = self.articlePrefix + item['docID'] + \
'.html?spss=newsapp&from=singlemessage'
elif item['type'] == 'video':
item['postURL'] = self.videoArticlePrefix + item['docID'] + \
'.html?spss=newsapp&from=singlemessage'
file.write(json.dumps(releatedocList, sort_keys=True,
indent=4, ensure_ascii=False))
def dealingArticleHotDiscuss(self, flow: mitmproxy.http.HTTPFlow, path, url):
if url.startswith(self.hotDiscussURL):
paramArr = path.split('?')[1].split('&')
docID = paramArr[len(paramArr) - 1].split('=')[1]
find_between(url, self.relatedArticleURL, '.html')
if not os.path.exists(self.getCurrentSearchTypePath() + '/ hotDiscuss'):
os.system(
'mkdir ' + self.getCurrentSearchTypePath() + '/hotDiscuss')
content = flow.response.get_content()
contentJson = json.loads(content)
hotDiscuss = contentJson['data']
if hotDiscuss != None:
hotDiscussName = self.getCurrentSearchTypePath() + '/hotDiscuss/' + \
docID + '.json'
with open(hotDiscussName, 'w') as file:
file.write(json.dumps(hotDiscuss, sort_keys=True,
indent=4, ensure_ascii=False))
def dealingComments(self, flow: mitmproxy.http.HTTPFlow, path, url):
if url.startswith(self.commentURLPreFix):
postID = find_between(
url, self.commentURLPreFix, self.commentURLSuffFix)
if not os.path.exists(self.getCurrentSearchTypePath() + '/hotCommentList'):
os.system('mkdir ' + self.getCurrentSearchTypePath() +
'/hotCommentList')
content = flow.response.get_content()
contentJson = json.loads(content)
hotCommentList = contentJson['hotCommentList']
if hotCommentList != None:
hotCommentListItemName = self.getCurrentSearchTypePath() + \
'/hotCommentList/' + postID + '.json'
with open(hotCommentListItemName, 'w') as file:
file.write(json.dumps(hotCommentList, sort_keys=True,
indent=4, ensure_ascii=False))
def dealingNeteaseAccount(self, flow: mitmproxy.http.HTTPFlow, path, url):
if url.startswith(self.netesaeAccountProfileURL):
content = flow.response.get_content()
contentJson = json.loads(content)
if contentJson != None:
hotCommentListItemName = self.getCurrentSearchTypePath() + NeteaseAccountJSON
with open(hotCommentListItemName, 'w') as file:
file.write(json.dumps(
contentJson, sort_keys=True, indent=4, ensure_ascii=False))
def dealingNeteaseAccountArticle(self, flow: mitmproxy.http.HTTPFlow, path, url):
if url.startswith(self.neteaseAccountArticleURL):
ename = find_between(url, self.neteaseAccountArticleURL, '/all')
content = flow.response.get_content()
contentJson = json.loads(content)
print('网易号:' + ename + ',用户名:' +
contentJson['subscribe_info']['tname'])
tagList = contentJson['tab_list']
for item in tagList:
item['postURL'] = self.articlePrefix + item['postid'] + \
'.html?spss=newsapp&from=singlemessage'
if contentJson != None:
hotCommentListItemName = self.getCurrentSearchTypePath() + NeteaseAccountArticleJSON
with open(hotCommentListItemName, 'w') as file:
file.write(json.dumps(
contentJson, sort_keys=True, indent=4, ensure_ascii=False))
def load(self, entry: mitmproxy.addonmanager.Loader):
ctx.log.info("addon 第一次加载")
def done(self):
ctx.log.info("addon 关闭或被移除,又或者 mitmproxy 本身关闭")
def getRelatedArticleRequestURL(self, skipID):
return self.relatedArticleURL + skipID + '.html'
def getHotDiscussRequestURL(self, docID):
return self.hotDiscussURL + docID
def getCommentRequestURL(self, postID):
return self.commentURLPreFix + postID + self.commentURLSuffFix
def getCurrentSearchTypePath(self):
path = self.currentSavePath + '/' + \
self.newsTypeConfig[self.currentNewsType]['folderName']
if not os.path.exists(path):
os.system('mkdir ' + path)
return path
def find_between(s, first, last):
try:
start = s.index(first) + len(first)
end = s.index(last, start)
return s[start:end]
except ValueError:
return ""
写本地服务用户获取数据
写一个基于 Flask 的服务,就两个接口:
#!/usr/bin/python3
import sys
sys.path.append("..")
from netease_news_suite.mitmproxy.common import DataBasePath, SearchConfigPath, AppiumPath, NeteaseAccountJSON, NeteaseAccountArticleJSON
from flask import Flask, jsonify, request
from werkzeug.serving import run_with_reloader
from gevent import monkey
from gevent.pywsgi import WSGIServer
from libs.foo import foo
import os
import json
monkey.patch_all()
app = Flask(__name__)
app.debug = True
app.secret_key = 'news_demo'
# 获取关键词
@app.route('/api/getArticlesForKeyword', methods=['GET'])
def getArticlesForKeyword():
# 获取参数
keyword = request.args.get('keyword')
# 设置搜索配置
setSearchConfig(keyword, 'keyword')
os.chdir(AppiumPath)
os.system('say 开始查找关键词' + keyword + '的新闻')
os.system(f'python3 neteaseNewsSpider_iOS.py -k {keyword} -t keyword')
articleList = []
# 获取文章列表
resultPath = DataBasePath + '/' + keyword + '/ZongHe/result.json'
if os.path.exists(resultPath):
with open(resultPath, 'r') as outfile:
articleList = json.load(outfile)
return jsonify(result=articleList), 200
# 获取用户
@app.route('/api/getInfoForUser', methods=['GET'])
def getInfoForUser():
# 获取参数
keyword = request.args.get('keyword')
# 设置搜索配置
setSearchConfig(keyword, 'user')
os.chdir(AppiumPath)
os.system('say 开始查找用户' + keyword + '的新闻')
os.system(f'python3 neteaseNewsSpider_iOS.py -k {keyword} -t user')
netesaeAccountInfo = {}
netesaeAccountArticleInfo = {}
# 获取用户信息
netesaeAccountInfoPath = DataBasePath + '/' + \
keyword + '/User' + NeteaseAccountJSON
if os.path.exists(netesaeAccountInfoPath):
with open(netesaeAccountInfoPath, 'r') as outfile:
netesaeAccountInfo = json.load(outfile)
# 获取用户文章列表
netesaeAccountArticleInfoPath = DataBasePath + '/' + \
keyword + '/User' + NeteaseAccountArticleJSON
if os.path.exists(netesaeAccountArticleInfoPath):
with open(netesaeAccountArticleInfoPath, 'r') as outfile:
netesaeAccountArticleInfo = json.load(outfile)
# 文章不存在处理
if not 'tab_list' in netesaeAccountArticleInfo:
netesaeAccountArticleInfo['tab_list'] = []
return jsonify(subscriptionInfo=netesaeAccountInfo, subscriptionArticleInfo=netesaeAccountArticleInfo), 200
def setSearchConfig(keyword, type):
config = {
"keyword": keyword,
"type": type,
}
with open(SearchConfigPath, 'w') as file:
file.write(json.dumps(
config, sort_keys=True, indent=4, ensure_ascii=False))
http_server = WSGIServer(('0.0.0.0', 12000), app)
@run_with_reloader
def run_server():
http_server.serve_forever()
界面部分
客户端这步非必需,也可简单使用 postman 或浏览器直接调用测试,这里只是为了方便给客户展示效果。
用 nw.js 或 Electron 生成一个跨平台的桌面应用,这里直接展示效果。
控制&服务端
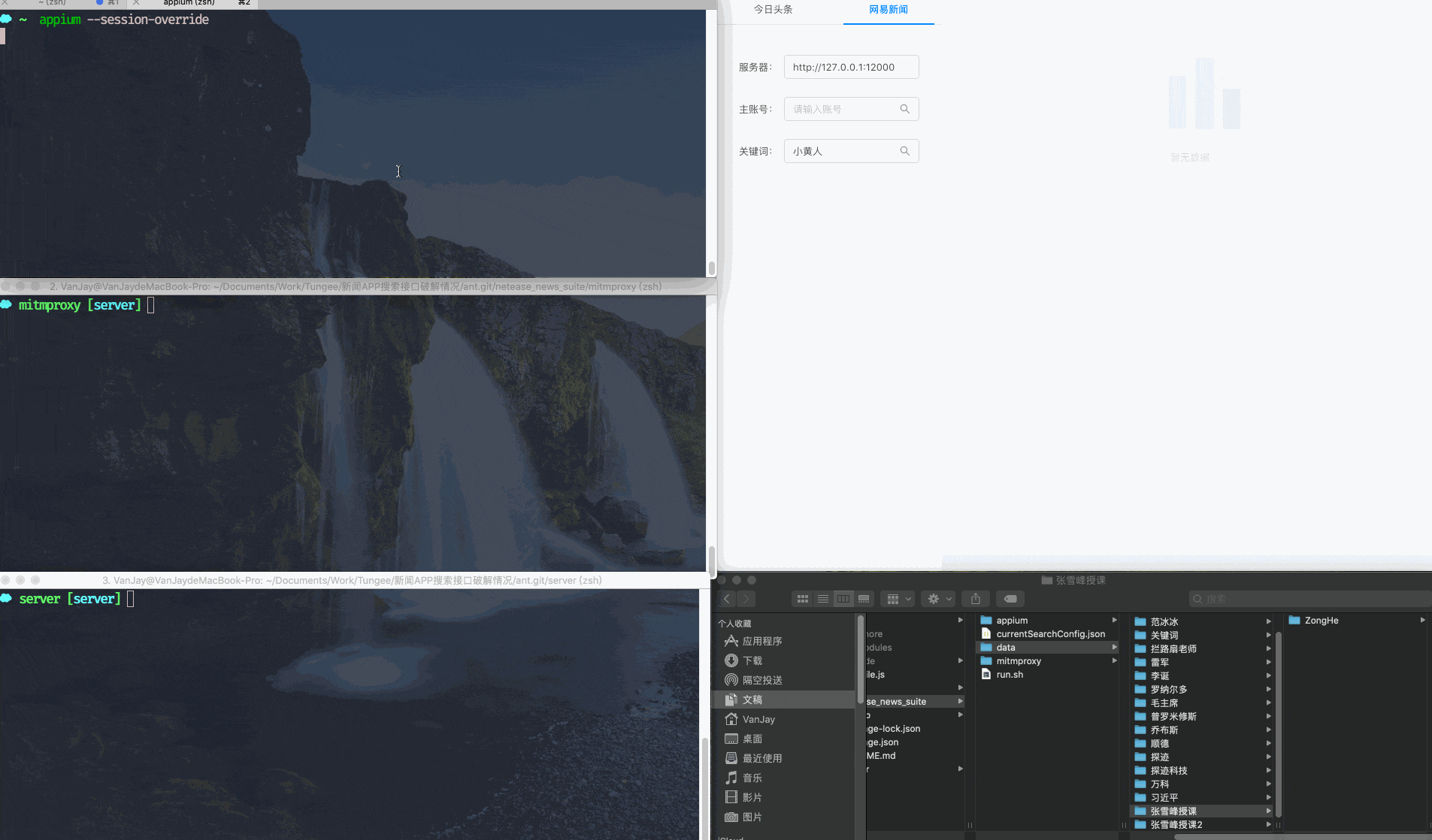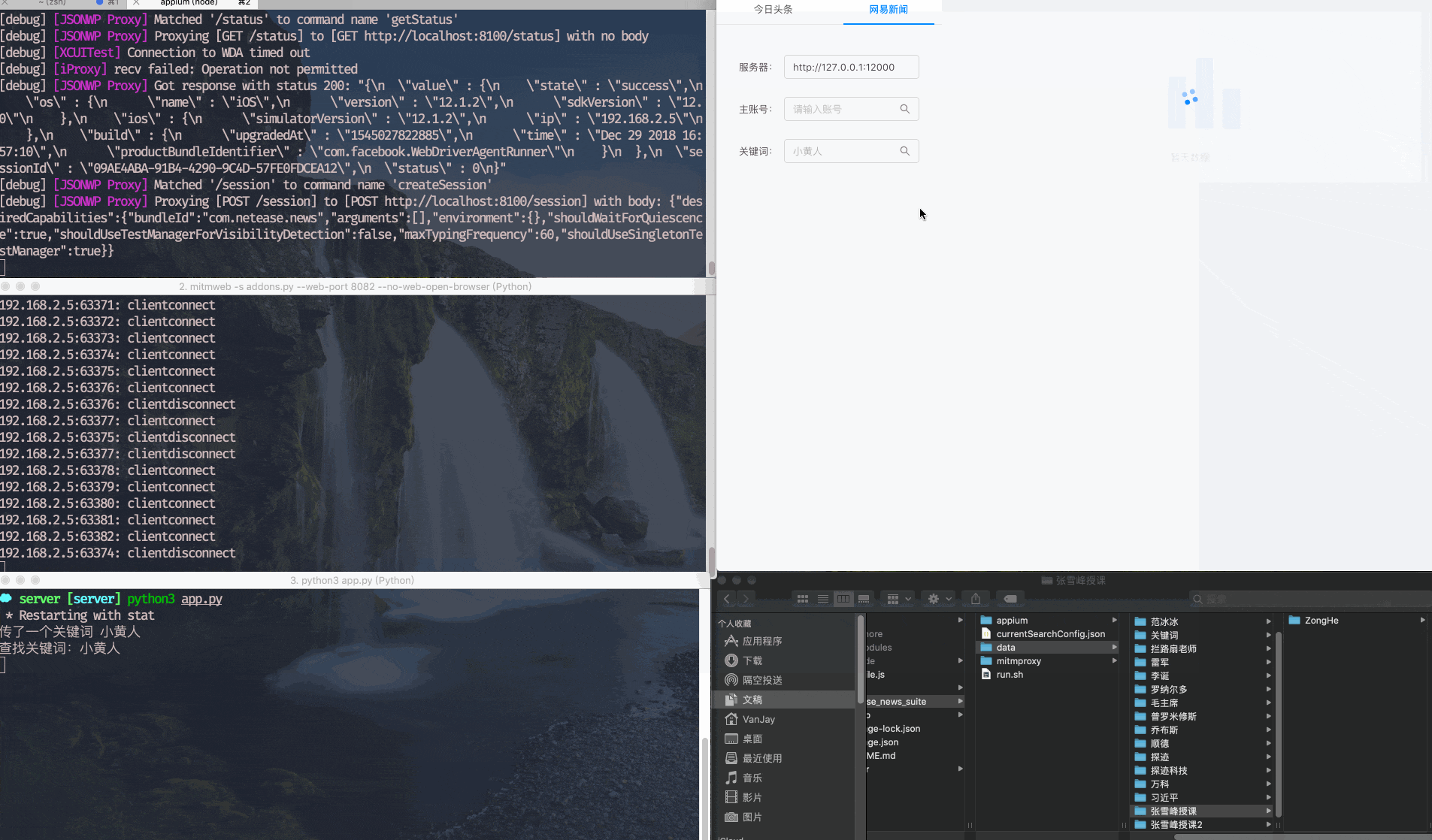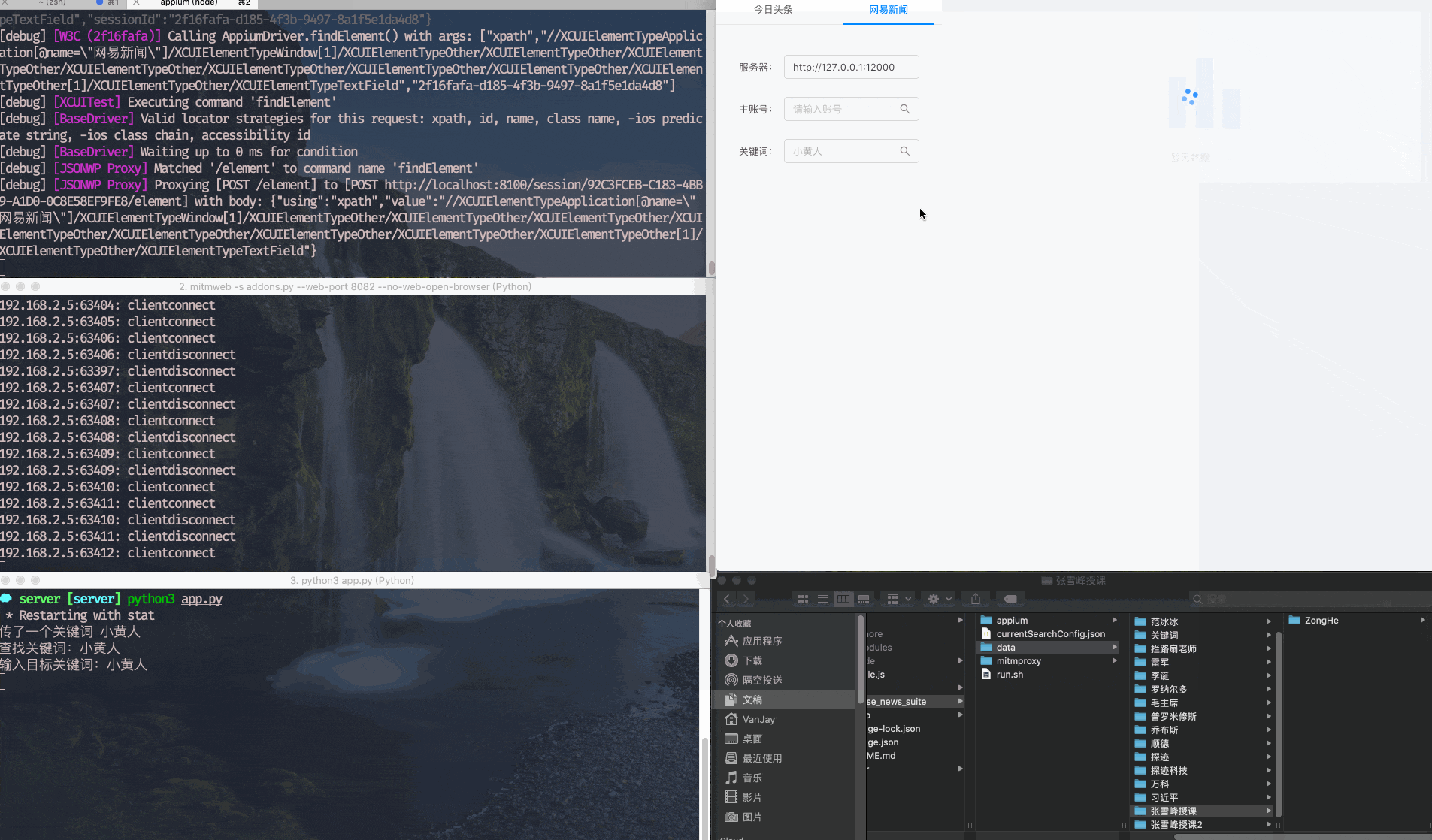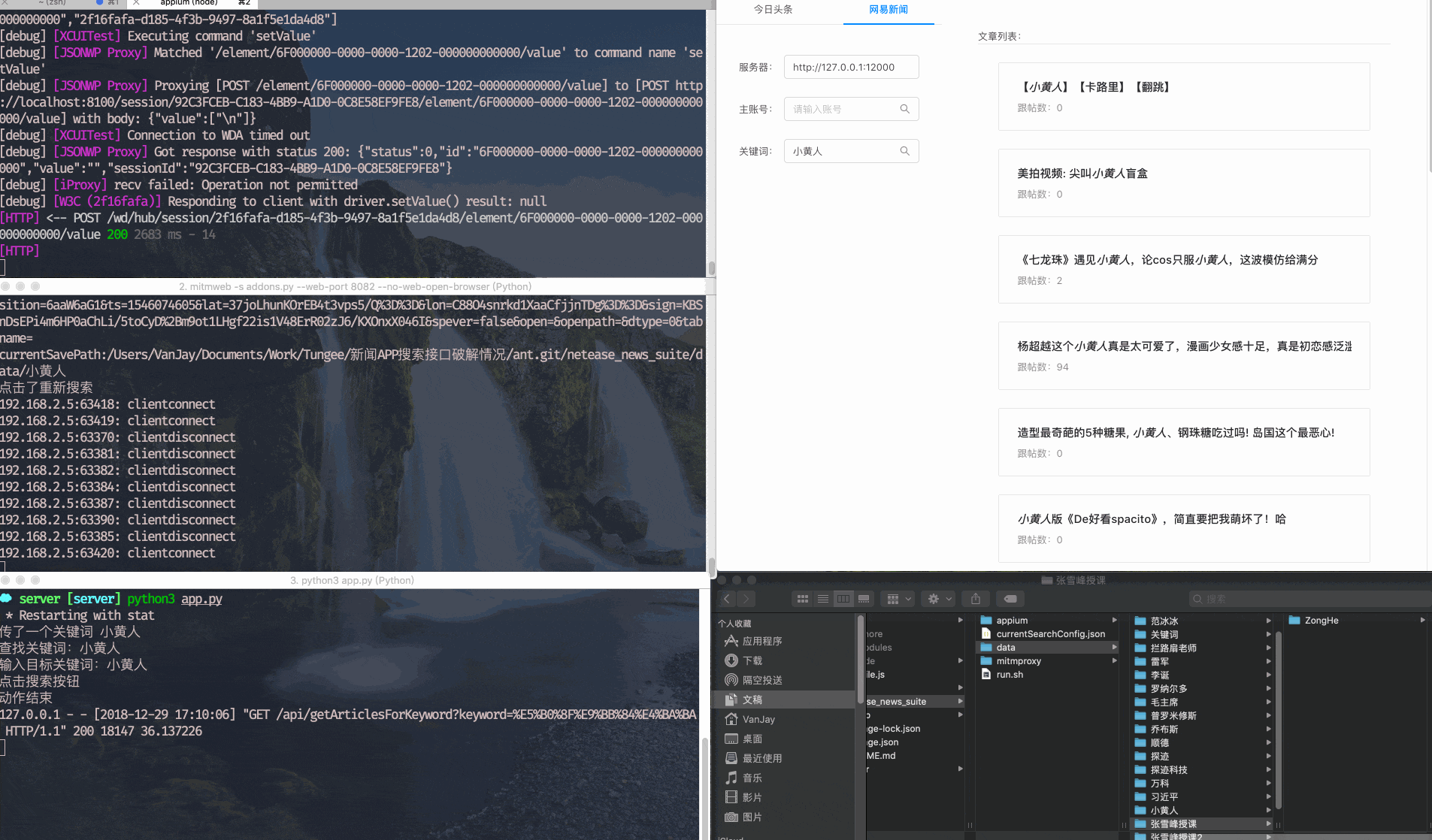
手机端

讨论
这个示例是用的 iPhone 完成的,当然用安卓真机或安卓模拟器都是可以的,我都有尝试,模拟器试了夜神模拟器和网易 MUMU 模拟器,但是用这个方案有障碍,就是部分新闻 APP 在检测到系统启用了网络代理后不进入应用或者不加载数据,也就意味着这个方案被夭折,但是如果这个项目真要形成,最终肯定是要服务器跑安卓模拟器或者真机设备来完成数据采集,因为全部使用 iPhone 的话,一不能使用 iOS 模拟器安装第三方APP,二必须要有 Mac 环境,大批量的话成本过于高昂,所以我暂时想到的是可以逆向 apk,hook 类似于检测是否启用了网络代理的判断函数,每次都返回”未使用代理”,或者修改安卓系统本身这样的系统 api,让所有 APP 都检测不到系统使用了网络代理,当然了,这只是我的猜想,具体检测逻辑尚未调研,个人认为这里说的第一种可行性很高,有难度但是不大,至少可以预知比逆向得到请求参数加密的方法和逻辑简单太多,如果你有更好的方案,欢迎留言讨论。